Google+
CJKV VBA IME for MS Word v 3.0
CJKV VBA IME for MS Word v 3.0
by WERTA© 2000–2012
DOWNLOAD
Instructions for use.
By
these macros you may enter any double-byte Asian characters and make simple conversion
of texts for East Asian languages. These macros are includes: Chinese,
Japanese, Korean, and Vietnamese units in the dot-format files.
Technical requirements
For
properly work of these macros you need MS Word software installed on your PC
with MS Office version not earlier than 2000. These macros have no digital signature,
so after installation, you need to change the lowest security settings of your
MS Word for work with VBA-macros, such as: (Tools => Macro => Security
=> Low). You can run any of these dot-files by the usual way (click) in
browser of file manager software. After opening the dot-file, you will see a
new toolbar. The path for supporting binary files and conversion tables is fixed
and determined as C:\ CJKV_VBA.

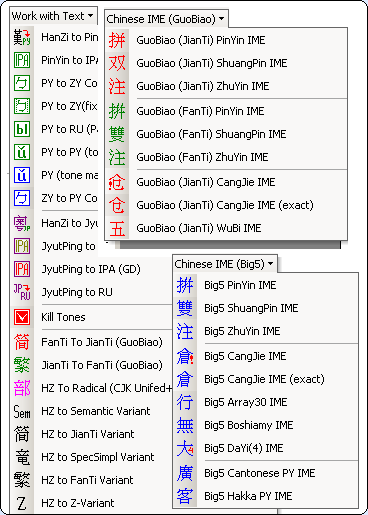
1. Chinese Input Methods for MS
Word.
1.1 List of IME
Format Description: A set of
characters (Ex. / Trad.) Input method.
Input methods (character set) for Simplified Chinese (GB2312):
Phonetic
(Mandarin)
GuoBiao (JianTi) PinYin
- standard Pinyin with using digitals for tones and input letter «v» instead of
«ü». Character set is GB2312. Simplified Chinese characters are available.
Keyboard layout is Latin letters. Text input mode is single ideographic characters
and you can also input some Chinese words (tone digits is not use for it).
GuoBiao (JianTi) ShuangPin
- input phoneme is available always with two keyboards clicks (called
ShuangPin). The first keypress is corresponds to PinYin initial. The second keypress
is corresponds to PinYin medial+final. Character set is GB2312. Simplified
Chinese characters are available. Text input mode is single ideographic characters
and you can also input some Chinese words (tone digits is not use for it).
GuoBiao (JianTi) ZhuYin -
input based on Zhuyin Zimu alphabet. Character set is GB2312. Simplified
Chinese characters are available. Keyboard layout is standard Zhuyin. Text input
mode is single ideographic characters only.
GuoBiao (FanTi) PinYin
- standard Pinyin, with using digitals for tones and input letter «v» instead
of «ü». Character set is GB2312. Traditional Chinese characters are available.
Keyboard layout is Latin letters. Text input mode is single ideographic characters
and you can also input some Chinese words (tone digits is not use for it).
GuoBiao (FanTi) ShuangPin
- input phoneme is available always with two keyboards clicks (called
ShuangPin). The first keypress is corresponds to PinYin initial. The second keypress
is corresponds to PinYin medial+final. Character set is GB2312. Traditional Chinese
characters are available. Text input mode is single ideographic characters and you
can also input some Chinese words (tone digits is not use for it).
GuoBiao (FanTi) ZhuYin
- input based on Zhuyin Zimu alphabet. Character set is GB2312. Traditional
Chinese characters are available. Keyboard layout is standard Zhuyin. Text input
mode is single ideographic characters only.
Structural
methods
GuoBiao (JianTi) CangJie
- input with CangJie system. The maximum length of the input string is 5
characters. Character set - GB2312. Simplified Chinese characters are available.
Keyboard layout is standard CangJie. The selection of characters for the input
list is performs by matching of the entered part of the coding CangJie stroke. The
input mode is single input of ideographic character only.
GuoBiao (JianTi) CangJie (exact)
- input with CangJie system. The maximum length of the input string is 5
characters. Character set is GB2312. Simplified Chinese characters are
available. Keyboard layout is standard CangJie. The selection of characters for
the input list is performs by both matching of the entered part of the encoding
CangJie stroke and the total length of encoding CangJie stroke. The input mode is
single input of ideographic character only.
GuoBiao (JianTi) WuBi
- input with Wubi system. The maximum length of the input string is 4
characters. Character set is GB2312. Simplified Chinese characters are
available. Keyboard layout is standard WuBi. Input modes is type of single ideographic
character only.
Input
methods (character set) for Traditional
Chinese:
Phonetic
(Mandarin)
Big5 PinYin
- standard Pinyin, with using digitals for tones and input letter «v» instead
of «ü». Character set is BIG5. Traditional Chinese characters are available.
Keyboard layout is Latin letters. Text input mode is typing of single
ideographic characters and you can also input some Chinese words (tone digits
is not use for it).
Big5 ShuangPin
- input phoneme is available always with two keyboards clicks (called
ShuangPin). The first keypress is corresponds to PinYin initial. The second keypress
is corresponds to PinYin medial+final. Character set is BIG5. Traditional Chinese
characters are available. Text input mode is typing of single ideographic characters
and you can also input some Chinese words (tone digits is not use for it).
Big5 ZhuYin
- input based on Zhuyin Zimu alphabet. Character set is BIG5. Traditional
Chinese characters are available. Keyboard layout is standard Zhuyin. Text input
mode is type of single ideographic character only.
Structural
methods
Big5 CangJie
- input with CangJie system. The maximum length of the input string is 5
characters. Character set - BIG5. Traditional Chinese characters are available.
Keyboard layout is standard CangJie. The selection of characters for the input
list is performs by matching of the entered part of the coding CangJie stroke. The
input mode is type of single ideographic character only.
Big5 CangJie (exact)
- input with CangJie system. The maximum length of the input string is 5
characters. Character set is BIG5. Traditional Chinese characters are available.
Keyboard layout is standard CangJie. The selection of characters for the input list
is performs by both matching of the entered part of the encoding CangJie stroke
and the total length of encoding CangJie stroke. The input mode is single input
of ideographic character only.
Big5 Array30
- input with Array30 system. The maximum length of the input string is 4
characters. Character set is BIG5. Traditional Chinese characters are available.
Keyboard layout is Array30. The selection of characters for the input list is
performs by matching of the entered part of the coding Array30 stroke. The input
mode is type of single ideographic character only.
Big5 Boshiamy
- input with Boshiamy system. The maximum length of the input string is 4
characters. Character set is BIG5. Traditional Chinese characters are available.
Keyboard layout is Boshiamy. The selection of characters for the input list is
performs by matching of the entered part of the coding Boshiamy stroke. The input
mode is type of single ideographic character only.
Big5 DaYi (4)
- input with DaYi system. The maximum length of the input string is 4
characters. Character set - BIG5. Traditional Chinese characters are available.
Keyboard layout is DaYi. The selection of characters for the input list is
performs by matching of the entered part of the coding DaYi stroke. The input
mode is type of single ideographic character only.
Phonetic
methods (Chinese dialects)
Big5 Cantonese PY -
input with Cantonese transcription without tone digits. Character set is BIG5.
Traditional Chinese characters are available. Keyboard layout is standard
Latin. The input mode is type of single ideographic character only.
Big5 Hakka PY
- input with transcription for Hakka dialects, with digital marking of tones
(1-6). Character set is BIG5. Traditional Chinese characters are available.
Keyboard layout is standard Latin. The input mode is type of single ideographic
character only.
Input
methods for UNICODE CJK extensions
PinYin IME (CJK Unified + ExtA) -
input with Standard Pinyin with digital Chinese tones designation (1-5) and with
letter «v» instead of «ü». A set of characters for enter is Unicode: CJK
Unified + CJK ExtA. Keyboard layout is standard Latin. The input mode is type of
single ideographic character only.
JyutPing IME (CJK Unified + ExtA)
- input with Standard Jyutping with digital Chinese tones designation (1-6). A
set of characters for enter is Unicode: CJK Unified + CJK ExtA. Keyboard layout
is standard Latin. The input mode is type of single ideographic character only.
CangJie IME (CJK Unified + ExtA)
- input with CangJie system. The maximum length of the input string is 5
characters. A set of characters for enter is Unicode: CJK Unified + CJK ExtA.
Keyboard layout is standard CangJie. The selection of characters for the input
list is performs by matching of the entered part of the coding CangJie stroke. The
input mode is type of single ideographic character only.
CangJie IME (CJK Unified + ExtA)
exact - input with CangJie system. The maximum length of
the input string is 5 characters. A set of characters for enter is Unicode: CJK
Unified + CJK ExtA. Keyboard layout is standard CangJie. The selection of
characters for the input list is performs by both matching of the entered part
of the encoding CangJie stroke and the total length of encoding CangJie stroke.
The input mode is single input of ideographic character only.
CangJie IME (ExtB) -
input with CangJie system. The maximum length of the input string is 5
characters. A set of characters to enter is Unicode CJK ExtB. Keyboard layout is
standard CangJie. The selection of characters for the input list is performs by
matching of the entered part of the coding CangJie stroke. The input mode is
type of single ideographic character only.
CangJie IME (ExtB) exact
- input with CangJie system. The maximum length of the input string is 5
characters. A set of characters to enter - Unicode CJK ExtB. Keyboard layout -
standard CangJie. The selection of characters for the input list is performs by
both matching of the entered part of the encoding CangJie stroke and the total
length of encoding CangJie stroke. The input mode is single input of
ideographic character only.
1.2 Conversion of text
For
conversion you need just select the text and press the button with macro.
Mandarin
HanZi to PinYin (CJK Unified + ExtA)
- selected characters will be converted to Pinyin transcription with digital
marking of Chinese tones and with text separator such as space, for example:
[HZ1] [HZ2] [HZ3] -> pinyin1 pinyin2 pinyin3
If
the Chinese character has more than one reading, the alternate versions of the
transcription will be enclosed in parentheses with comma separator inside, for
example:
[HZ1] [HZ2] [HZ3] -> pinyin1 (pinyin2_1,
pinyin2_2, pinyin2_3) pinyin3
For
conversion of Chinese ideographs are available following Unicode ranges: CJK
Unified + CJK ExtA.
For
example:
我喜欢电脑游戏
wo3 xi3 huan1 dian4
nao3 you2 (xi4 , hu1 , hui1)
PinYin to IPA -
this function is converts Pinyin phonemes with a digital Chinese tones designation
to the symbols of IPA system.
For
example:
wo3 xi3 huan1 dian4 nao3 you2 xi4
wuɔ²¹⁴ ɕʅ²¹⁴ huɑn⁵⁵ tiɛn⁵¹ nɑʊ²¹⁴ jɤʊ¹⁵ ɕʅ⁵¹
PY to ZY - this
function is converts Pinyin phoneme with digital Chinese tones designation in
the stroke of Zhuyin Zimu alphabet.
For
example:
wo3 xi3 huan1 dian4 nao3 you2 xi4
ㄨㄛˇ ㄒㄧˇ ㄏㄨㄢ
ㄉㄧㄢˋ ㄋㄠˇ ㄧㄡˊ
ㄒㄧˋ
PY to ZY (fixed) -
this function is converts Pinyin phoneme with digital Chinese tones designation
in the stroke of Zhuyin Zimu alphabet with fixed positions for four character
cells in resulting string. I.e. if the medial phoneme zero, it will be inserted
instead by the Asian monospace gap for aligning.
For
example:
wo3 xi3 huan1 dian4 nao3
| ㄨㄛˇ|ㄒㄧ ˇ| ㄏㄨㄢ |ㄉㄧㄢˋ| ㄋ ㄠˇ|
PY to RU - this
function is converts Pinyin phonemes with a digital Chinese tones designation
in the Palladius Cyrillic transcription system stroke with digital symbolic for
tones designation.
For
example:
wo3 xi3 huan1 dian4 nao3 you2 xi4
во3
си3 хуань1 дянь4 нао3 ю2 си4
PY to PY (tone marks) -
this function is converts Pinyin phonemes with the digital designation of
Chinese tones in the stroke of standard Putonghua Pinyin with diacritical tone symbols
placed under the vowels.
For
example:
wo3 xi3 huan1 dian4 nao3 you2 xi4
wǒ
xǐ huān diàn nǎo yóu xì
PY (tone marks) to PY -
this function is converts string of standard Putonghua Pinyin with diacritical
tone symbols placed under the vowels in the equivalent Pinyin stroke with a
digital designation of Chinese tone.
For
example:
wǒ
xǐ huān diàn nǎo yóu xì
wo3 xi3 huan1 dian4 nao3 you2 xi4
ZY to PY (only one phoneme)
- this function is converts a single phoneme text typed in Zhuyin Zimu alphabet
into a phoneme typed with a standard Pinyin and with digital designation of
Chinese tone.
For
example:
ㄉㄧㄢˋ => dian4
Kill Tones
- this function is removes symbols indicated the tone designations used in
transcription system PinYin or ZhuYin.
For
example:
wo3 xi3 huan1 dian4 nao3 you2 xi4
(or)
wǒ
xǐ huān diàn nǎo yóu xì
---------------------------------
wo xi huan dian nao you xi
Cantonese
HanZi to JyutPing (CJK Unified +
ExtA) - selected characters will be converted to Jyutping
transcription with digital designation of Cantonese tone and with text separator
such as space, for example:
[HZ1]
[HZ2] [HZ3] -> jyutping1 jyutping2 jyutping3
If
the character has more than one reading, the alternate versions of the
transcription will be enclosed in parentheses with comma separator inside, for
example:
[HZ1]
[HZ2] [HZ3] -> jyutping1 (jyutping2_1, jyutping2_2) jyutping3
Characters
that are available for conversion are in Unicode: CJK Unified + CJK ExtA.
For
example:
我喜欢电脑游戏
ngo5 hei2 fun1 din6 nou5 jau4 (fu1, hei3)
JyutPing to IPA (GD)
- this function converts a digital transcription Jyutping with digital designation
of Cantonese tone into IPA string (Guandong)
For
example:
baak1
ging1 si6 zung1 gwok3 dik1 sau2 dou1
pa:k⁵ kiŋ⁵⁵ si¹¹ tɕʊŋ⁵⁵ kʷɔk³ tik⁵ sɐu²⁵ tou⁵⁵
JyutPing to IPA (HK)
- this function converts a digital transcription Jyutping with digital designation
of Cantonese tone into IPA string (HK)
For
example:
baak1
ging1 si6 zung1 gwok3 dik1 sau2 dou1
pa:k⁵ kiŋ⁵⁵ si¹¹ tsʊŋ⁵⁵ kʷɔk³ tik⁵ sɐu²⁵ tou⁵⁵
JyutPing to RU -
this function converts Jyutping with digital indication of Cantonese tone into
Cyrillic transcription for Cantonese.
For
example:
ngo5 hei2 fun1 din6 nou5 jau4 fu1
нго5
хэй2 фунь1 тинь6 ноу5 яу4 фу1
Ideographs
conversion
FanTi to JianTi (GuoBiao) -
this function is converts the traditional Chinese characters into simplified
form (GB2312 charset only).
For
example:
我喜歡電腦游戲
我喜欢电脑游戏
JianTi to FanTi (GuoBiao) -
this function is converts the simplified Chinese characters into traditional
form (GB2312 charset only).
For
example:
我喜欢电脑游戏
我喜歡電腦游戲
HZ to Radical (CJK Unified + ExtA) -
this function is converts Chinese characters from the ranges Unicode: CJK
Unified + CJK ExtA into Bushou character from the list of 214 Kang Xi radicals.
The radical characters of Chinese ideographs are determined in accordance with
sorting within the Unicode standard.
For
example:
北京是中国的首都
匕亠日丨囗白首邑
HZ to Semantic Variant -
this function is converts a Chinese character from the ranges of Unicode: CJK
Unified + CJK ExtA into semantic variant.
For
example:
简
=> 耕
HZ to JianTi Variant
- this function is converts Chinese character from the ranges of Unicode: CJK
Unified + CJK ExtA into a simplified form.
For
example:
簡體漢字 =>
简体汉字
HZ to SpecSimpl Variant
- this function is converts Chinese character from the ranges of Unicode: CJK
Unified + CJK ExtA into a special simplified form (for example: Japanese
shintaiji, ryakuji).
For
example:
龍 =>
竜
HZ to FanTi Variant
- this function is converts Chinese character from the ranges of Unicode: CJK
Unified + CJK ExtA into a traditional form.
For
example:
简体汉字
=>簡體漢字
HZ to Z-Variant
- this function is converts Chinese character from the ranges of Unicode: CJK
Unified + CJK ExtA into a Z-variant form.
For
example:
繁
=> 緐
CJK HZ to Compatibility Char
- this function is converts Chinese character from the ranges of Unicode: CJK
Unified + CJK ExtA into a compatibility form.
Compatibility Char to CJK HZ
- this function is converts compatibility form of Chinese character into a
usual character form from Unicode ranges: CJK Unified + CJK ExtA.
Conversions
for CangJie
ABC to CJ Code -
this text function is converts the Latin alphabet characters into the
hieroglyphic key symbols of CangJie input system.
For
example:
LMP
YRF
中一心 卜口火
CJ code to ABC
- this text function is converts the hieroglyphic key symbols of CangJie input
system in the Latin alphabet characters.
For
example:
中一心 卜口火
LMP
YRF
HZ to CJ Code (ABC) (CJK Unified +
ExtA) - this text function is converts the Chinese characters
from the ranges Unicode: CJK Unified + CJK ExtA into CangJie system encoding
string using Latin alphabet symbols.
For
example:
北京
=> LMP YRF
Other
HanZi to Unicode (Dec)
- this function is converts selected Chinese characters in decimal code. After
conversion between obtained numerical values the space separators will be
placed.
For
example:
北京是中国的首都
21271
20140 26159 20013 22269 30340 39318 37117
HanZi to Unicode (Hex) -
this function is converts selected Chinese characters in hexadecimal code.
After conversion between obtained numerical values the space separators will be
placed.
For
example:
北京是中国的首都
5317
4EAC 662F
4E2D 56FD 7684 9996 90FD
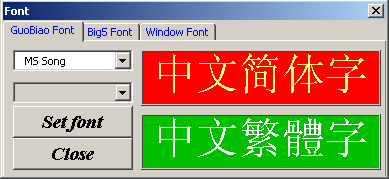
1.3 Select fonts
Font - this function
is allows to select fonts to display the input text and text in the input form.
Selecting a font character set for GB2312
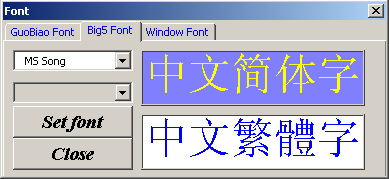
Selecting a font character set for BIG5
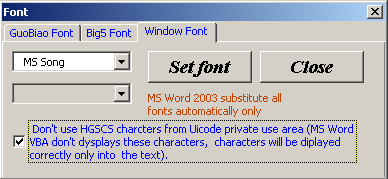
Selecting a font to display text in the input
form
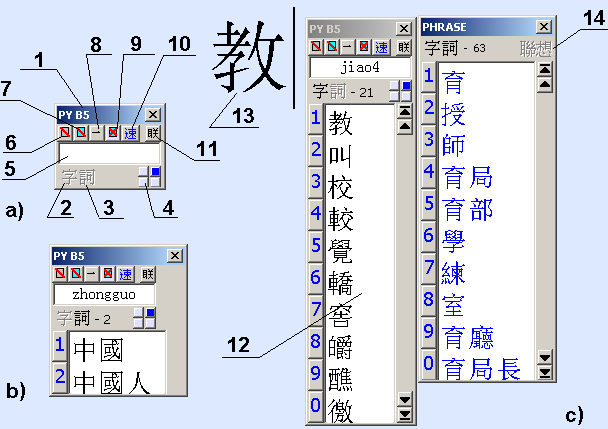
1.4 Input form
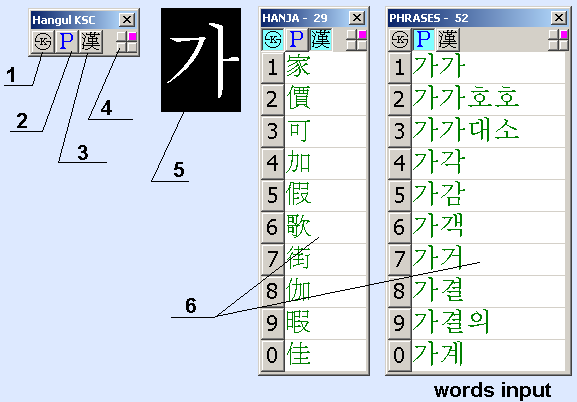
1
- short name of active IME
2
- one-char mode indicator
3
- words-mode indicator (only for Pinyin) - b)
4
- indicator of the input form position on the screen
5
- input text box
6
- reset the selection list after closing the related words form
7
- close the form with related words after the insertion char in the text
8
- just insert into the text, if the list of candidate has only one char
9
- disable the input of related words
10
- insert into the text first character from selection candidates list
11
- button to activate the LianXiang-mode for entering related words
12
- selection candidates list (words or characters)
13
- character typed in the text
14
- enable LianXiang-mode indicator
a) - main input form, c) - related words input form.
2. Japanese
Input Methods for MS Word.
2.1 List of
IME
Japanese Romaji -
this is kana input by using Latin transcription (Romaji). Character input modes
(Hira, Kata, HW-Kata, Kanji) can be switched by appropriate buttons on the
input form. Default kana input is hiragana mode. Note, that sometimes to enter
the closing syllable symbol ん (-n) you need to double press N. Reset
input buffer by pressing Esc when you want. You can also activate the kanji input
mode with the selection candidates list displayed on the input form.
Japanese Hiragana
- this is kana input by using Latin transcription (Romaji). Character input
modes (Hira, Kata, HW-Kata, Kanji) can be switched by appropriate buttons on
the input form. Default kana input is hiragana mode. Reset input buffer by
pressing Esc when you want. You can also activate the kanji input mode with the
selection candidates list displayed on the input form.
Japanese FourCorner -
this is the input of kanji with 4Corner system (Four
Corners). The maximum length of the input string is 5 characters. Characters
set for input is (0-9). Additional input also is available for the Japanese
kana characters layout. You can input kanji from the selection list by pressing
a number key. But it will be available when the length of the 4Corner encoding string
will reach 5 characters. If the length of 4Corner encoding string is less than
5, you can input kanji by mouse click.
2.2
Conversion of text
You
need just select the text and press the button with macro.
Hiragana to Romaji (simple) -
this text function is converts the hiragana text into romaji text string (without
analysis of kana characters neighboring in the converted text)
For
example:
ぼくのせんせいがです
bokunosenseigadesu
Katakana to Hiragana -
this text function is converts hiragana text string into katakana text string.
For
example:
ボクノセンセイガ
ぼくのせんせいが
Hiragana to Katakana
- this text function is converts katakana text string into hiragana text
string.
For example:
ぼくのせんせいが
ボクノセンセイガ
Hiragana to HalfW Katakana
- this text function is converts hiragana text string into half-width katakana
text string.
For
example:
ぼくのせんせいが
ボクノセンセイガ
Kanji to Radical -
this text function is converts kanji into the radical char from the list of 214
Kang Xi radicals. The radical characters are determined in accordance with
sorting into the Unicode standard. Available charset for conversion is CJK
Unifed Ideographs.
For
example:
著書南嶋探験
艸曰十山手馬
Kyutaiji to Sintaiji -
this text function is converts kanji from traditional style to simplified Japanese
kanji style.
For
example:
驗=>験
Sintaiji to Kyutaiji -
this text function is converts kanji from simplified Japanese Kanji style to
traditional style.
For
example:
験=>驗
Kanji to Unicode (Dec)
- this function is converts selected kanji into decimal code. After conversion
the space separators will be placed among obtained numerical values.
For
example:
著書南嶋探験
33879
26360 21335 23947 25506 39443
Kanji to Unicode (Hex)
- this function is converts selected Chinese characters in hexadecimal code.
After conversion the space separators will be placed among obtained numerical
values.
For
example:
著書南嶋探験
8457
66F8 5357 5D8B 63A2 9A13
2.3 Select
fonts
Font - this function
is allows to select fonts to display the input text and text in the input form.
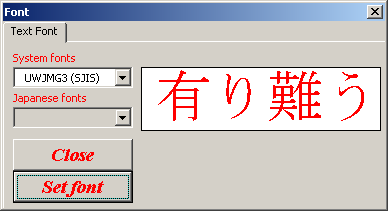
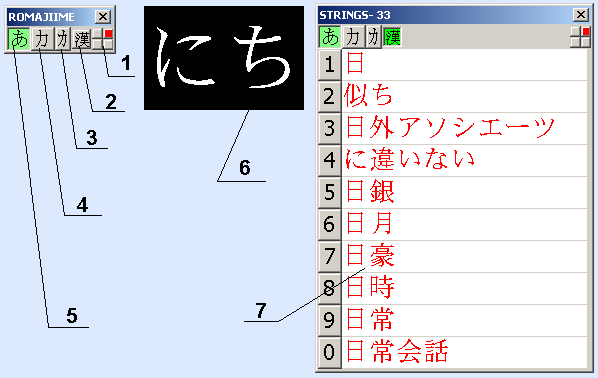
2.4 Input form
1
- indicator of input form position on the screen
2
- indicator for enabling kanji mode
3
- indicator for enabling half-width katakana mode
4
- indicator for enabling katakana mode
5
- indicator for enabling hiragana mode
6
- text input
7
- list of candidates for single kanji or words
8
- short name of the input method.
3. Korean
Input Methods for MS Word.
3.1 List of IME
Hangul (BeolSik)
- input Hangul phonemes with a standard Korean keyboard layout (Beol Sik). You
can reset the input buffer by pressing Esc. It is possible to activate the hanja
input mode from the selection list (press appropriate button). You can activate
the input for simple words by the entered first Hangeul syllable. Also you can
enter all Hangul phonemes included in the Unicode standard. Button on the input
form may enable KSC-only mode to filtering Hangeul phonemes input. Thus it will
be input with Hangul phonemes only included into Korean national standard (KSC).
Hangul (LatinABC)
- input Hangul phonemes with a simplified Korean romanization scheme (like for isolated
phonemes) by Latin keyboard layout. You can reset the input buffer by pressing
Esc. It is possible to activate the hanja input mode from the selection list
(press appropriate button). You can activate the input for simple words by the entered
first Hangeul syllable. Also you can enter all Hangul phonemes included in the
Unicode standard. Button on the input form may enable KSC-only mode to filtering
Hangeul phonemes input. Thus it will be input with Hangul phonemes only
included into Korean national standard (KSC).
3.2 Conversion of text
For
conversion you need just select the text and press a button with macro.
Hangul to String -
this text conversion function is splits Hangeul phonemes into string of Hangul
Jamo letters that included in this phoneme.
For
example:
곺 => ㄱ ㅗ ㅍ
Hangul (Isolated) to Romanization -
this text conversion function is translates a string of Hangeul phonemes into Romanization
Latin symbols without the analysis of neighboring phonemes position in the
Korean text. After the conversion the text delimiter will be a space symbol among
the resulting Romanized phonemes.
For
example:
한글 자모
HAN
GEUL JA MO
Hangul (Isolated) to Cyrillization
- this text conversion function is translates a string of Hangeul phonemes into
Cyrillic transcription (is not Polivanov
system) without the analysis of neighboring phonemes position in the Korean
text. After the conversion the text delimiter will be a space symbol among the resulting
Cyrillic transcription.
For
example:
한글 자모
ХАН КЫЛЬ ЧА МО
Latin
String to Hangul - this text conversion function is translates the
Romanization string into Hangeul phoneme.
For
example:
HAN
GEUL JA MO
한글 자모
Type All 11172 Hangul chars
- test for the output of all Hangeul phonemes included in the Unicode standard
(this function will take few seconds)
For
example:
가,
각,
갂,
갃,
간,
갅,
갆,
갇,
갈
... (output in one column)
Hangul to Unicode (Dec)
- this function is converts selected Hangeul phonemes into decimal code. After
conversion the space separators will be placed among obtained numerical values.
For
example:
한글 자모
54620
44544 51088 47784
Hangul to Unicode (Hex)
- this function is converts selected Hangeul phonemes into hexadecimal code.
After conversion the space separators will be placed among obtained numerical
values.
For
example:
한글 자모
D55C
AE00 C790 BAA8
Hanja to Unicode (Dec)
- this function is converts selected hanja into decimal code. After conversion
the space separators will be placed among obtained numerical values.
For
example:
韩契字母
38867
63753 23376 27597
Hanja to Unicode (Hex)
- this function is converts selected hanja into hexadecimal code. After
conversion the space separators will be placed among obtained numerical values.
For
example:
韩契字母
97D3
F909 5B50 6BCD
Hanja to Hangul
- selected hanja will be converted to Hangeul phoneme transcription with text separator
such as space. If the hanja has more than one Hangeul reading, the alternate
versions of the transcription will be enclosed in parentheses with comma
separator inside. Available charsets for conversion are: CJK Unifed Ideographs
+ CJK Ext A.
For
example:
韩契字母
한글 자모
Hanja to Radical (Unicode)
- this text function is converts hanja to the radical character from the list
of 214 Kang Xi radicals. The radical characters are determined in accordance
with sorting into the Unicode standard. Available charset for conversion is CJK
Unifed Ideographs.
For
example:
韩契字母
韦大子毋
3.3 Select fonts
Font - this function
is allows to select fonts to display the input text and text in the input form.
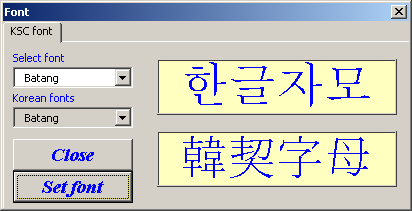
3.4 Input form
1
- button to activate the KSC-only mode filtration
2
- button to activate the input of simple words
3
- button to activate the Hanja input mode
4
- indicator of input form position on the screen
5
- typed Hangeul phoneme
6
- the list of Hanja candidates (or Hangeul words) for input
4. Vietnamese
Input Methods for MS Word.
4.1 List of IME
Telex (VISCII)
- the basis of the layout is standard Latin. You can input Vietnamese vowels with
the Telex system. Tone modifiers of vowels are keys: F, S, X, J, R. Vowel
modifiers for Â, Ê, Ô - respectively second pressing A, E, O. The modifier for
Ư, Ơ - W letter for both, after O and U press respectively. The modifier for Đ
- double press of D key. To correctly display characters you required a font
with VISCII single-byte characters encoding (this font is attached to the macro
script C:\CJKV_VBA\VIETNAMESE\Viet.ttf). Chinese ideographs character input
mode is not available.
VIQR fast (VISCII)
- the basis of the layout is standard Latin. You can input Vietnamese vowels with
the VIQR system (fast variant, max. two clicks). To correctly display characters
you required a font with VISCII single-byte characters encoding (this font is attached
to the macro script C:\CJKV_VBA\VIETNAMESE\Viet.ttf). Chinese ideographs character
input mode is not available.
Telex (Unicode)
- the basis of the layout is standard Latin. You can input Vietnamese vowels with
the Telex system. Tone modifiers of vowels are keys: F, S, X, J, R. Vowel
modifiers for Â, Ê, Ô - respectively second pressing A, E, O. The modifier for
Ư, Ơ - W letter for both, after O and U press respectively. The modifier for Đ
- double press of D key. To correctly display characters you required a Unicode
font with Extended Latin symbols (Times New Roman). Chinese ideographs character
input mode is available.
VIQR fast (Unicode)
- the basis of the layout is standard Latin. You can input Vietnamese vowels with
the VIQR system (fast variant, max. two clicks). Also you need to have any
Unicode fonts with extended Latin characters (Times New Roman). Chinese
ideographs character input mode is available.
4.2 Conversion of text
For
the conversion you need just select the text (except the test output functions)
and press a button with macro.
Type VISCII vowels LowCase
- test output of all Vietnamese vowels list in all tone cases with VISCII single-byte
encoding (lower case characters).
For
example:
a à á ạ ã ả
â ầ ấ ậ ẫ ẩ
ă ằ ắ ặ ẵ ẳ
e è é ẹ ẽ ẻ
ê ề ế ệ ễ ể
o ò ó ọ õ ỏ
ô ồ ố ộ ỗ ổ
ơ ờ ớ ợ ỡ ở
u ù ú ụ ũ ủ
ư ừ ứ ự ữ ử
i ì í ị ĩ ỉ
y ỳ ý ỵ ỹ ỷ
Type VISCII vowels UpCase
- test output of all Vietnamese vowels list in all tone cases with VISCII single-byte
encoding (upper case characters).
For example:
A À Á Ạ Ã Ả
 Ầ Ấ Ậ Ẫ Ẩ
Ă Ằ Ắ Ặ Ẵ Ẳ
E È É Ẹ Ẽ Ẻ
Ê Ề Ế Ệ Ễ Ể
O Ò Ó Ọ - Ỏ
Ô Ồ Ố Ộ Ỗ Ổ
Ơ Ờ Ớ Ợ Ỡ Ở
U Ù Ú Ụ Ũ Ủ
Ư Ừ Ứ Ự Ữ Ử
I Ì Í Ị Ĩ Ỉ
Y Ỳ Ý - - -
Type Unicode vowels LowCase
- test output of all Vietnamese vowels list in all tone cases with Unicode double-byte
encoding (Extended Latin symbols, lower case characters).
For
example:
a à á ạ ã ả
â ầ ấ ậ ẫ ẩ
ă ằ ắ ặ ẵ ẳ
e è é ẹ ẽ ẻ
ê ề ế ệ ễ ể
o ò ó ọ õ ỏ
ô ồ ố ộ ỗ ổ
ơ ờ ớ ợ ỡ ở
u ù ú ụ ũ ủ
ư ừ ứ ự ữ ử
i ì í ị ĩ ỉ
y ỳ ý ỵ ỹ ỷ
Type Unicode vowels UpCase
- test output of all Vietnamese vowels list in all tone cases with Unicode double-byte
encoding (Extended Latin symbols, upper case characters).
For example:
A À Á Ạ Ã Ả
 Ầ Ấ Ậ Ẫ Ẩ
Ă Ằ Ắ Ặ Ẵ Ẳ
E È É Ẹ Ẽ Ẻ
Ê Ề Ế Ệ Ễ Ể
O Ò Ó Ọ Õ Ỏ
Ô Ồ Ố Ộ Ỗ Ổ
Ơ Ờ Ớ Ợ Ỡ Ở
U Ù Ú Ụ Ũ Ủ
Ư Ừ Ứ Ự Ữ Ử
I Ì Í Ị Ĩ Ỉ
Y
Ỳ Ý
Ỵ Ỹ Ỷ
VIQR to VISCII -
this function performs conversion of text strings encoded by VIQR sequence into
Vietnamese characters single-byte encoding VISCII. To work correctly you need to
have a font with VISCII single-byte character encoding (viet.ttf).
For
example:
Tie^'ng Vie^.t
Tiếng Việt
VIQR to Unicode -
this function performs conversion of text strings encoded by VIQR sequence into
Unicode Vietnamese letters. To work correctly you need to have any Unicode font
with extended Latin characters (Times New Roman).
For
example:
Tie^'ng Vie^.t
Tiếng Việt
VISCII to Unicode
- this text function is converts VISCII encoded string to a string with Unicode
Vietnamese letters.
Unicode to VISCII -
this text function is converts Unicode strings into a string encoded by VISCII
single-byte character set. For correctly working of this function you need to have
a font with single-byte character encoding VISCII (viet.ttf).
VISCII to VIQR
- this text function is performs the conversion of single byte Vietnamese text
(VISCII) into the VIQR encoding text.
For
example:
Tiếng Việt
Tie^'ng Vie^.t
Unicode to VIQR -
this text function is performs the conversion of Vietnamese text (Unicode) into
the VIQR encoding text.
For
example:
Tiếng Việt
Tie^'ng Vie^.t
HanNom to VIET string -
this text function is converts the selected Chinese characters from the ranges of
Unicode: CJK Unified + CJK ExtA into corresponding Vietnamese reading. If the Chinese
character has more than one reading, the alternate versions of the Vietnamese transcription
will be enclosed in parentheses with separator by comma inside.
For
example:
越南
=> việt nam
4.3 Input form
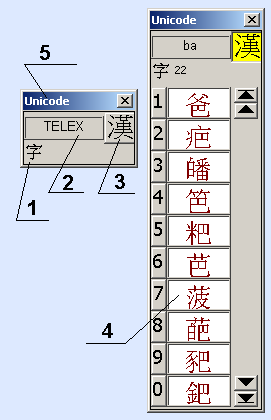
2
- name of input method (or input text field)
3
- button for activate of Chinese ideographs input mode
4
- Chinese ideographs selection list
5
- indicator of characters encoding used for input.
FEEDBACK
WERTA (C), 2000-2013, E-Mail: werta666@pisem.net